已阅读
全网最详细的网站性能(架构)优化手段
网站的性能测试
性能测试是性能优化的前提,也是性能优化结果的检查和度量标准。温馨提示:本文内容有点长,请耐心看完或者先收藏。
性能测试的常用指标:
-
响应时间
-
并发数目
-
吞吐量。常用的吞吐量指标:
①TPS(每秒事务数)、 ②HPS(每秒Http请求数)、 ③QPS(每秒查询数,)
-
性能计数器。常用的性能计数器有:system Load、对象和线程数、CPU使用、内存使用、磁盘和网络IO等指标。 性能测试的几个参考点:
-
性能测试
-
负载测试:系统的某项或者多想性能指标达到安全临界值时的并发数
-
压力测试
-
稳定性测试。PS:稳定性测试主要是长时间给系统一定的压力,看系统是否正常运行。
网站的性能优化三维度
-
浏览器访问优化
-
应用服务器性能优化
-
存储优化
前端常用的优化方式
-
减少Http请求
减少Http请求的主要手段是合并CSS、合并JS、合并图片(页面引用时使用CSS偏移)
-
使用浏览器缓存
通过设置Http头中的Cache-Control和Expires的属性。静态资源的更新不要直接更新文件内容,要通过更改文件名的方式更新。更新讲台资源的时候使用逐量更新。
-
启用压缩
使用GZIP压缩,在服务端对文件进行压缩,在浏览器端对文件解压缩可以减少通信传输的数据量。但是该种方式会对服务器产生一定的压力,在款低啊良好而服务器资源不足的情况下要权衡考虑。
-
CSS文件放在页面最上面,js脚本放在页面最下面
浏览器会在下载完全部的CSS之后才会对页面进行渲染,所以最好的方式是把CSS放在页面最上面;但是JS则相反(如果页面解析时就要用的js还是要放在最上面)。
-
减少Cookie传输
比如用户的登录信息,可以考虑使用拦截器,在用户登录的时候把登录信息和用户的相关信息存放在ThreadLocal里面。
-
CDN加速
CDN的本质就是把资源放在离用户最近的地方,CDN能够缓存的一般是静态资源,如图片、文件、CSS、js脚本,静态网页。
-
反向代理
反向代理服务器的两个用途: ①保护网站安全; ②配置缓存功能可以加速web请求; ③负载均衡,可以提高网站的并发数
后台服务器常用的优化方式
-
缓存
-
集群
-
异步
-
代码优化
-
存储优化
缓存相关知识
后台性能优化的第一定律:优先考虑使用缓存优化性能。
-
缓存的本质
-
缓存的合理使用
-
缓存可用性
-
缓存的常见问题处理与优化
-
分布式缓存架构
缓存的本质
缓存的本质就是一个内存Hash表,数据以一对Key\Value键值对存储在内存Hash表中。主要用户存放读写比很高、很少变化的数据,网站数据通常遵循“二八定律”,即80%的访问落在20%的数据上,因此,将这20%的数据缓存起来,可以很好的改善系统性能。
合理的使用缓存
合理的使用缓存对提高系统性能有很多好处,但是不合理的使用缓存反而会成为系统的累赘甚至风险。滥用缓存的三种情况如下:
-
频繁修改的数据
数据的读写比至少应该是2:1以上,即写入一次缓存,在数据更新前至少读写两次,缓存才有意义。真正实践中这个比例可能会更高。
-
没有热点的访问
如果应用系统访问数据没有热点,不遵循二八定律,即大部分数据访问并没有集中在小部分数据中,那么缓存也没有意义,因为大部分数据还没有被再次访问就已经被挤出缓存了。
-
数据的不一致与脏读
写入缓存的数据最好能容忍一定时间的数据不一致,一般情况下最好对缓存的数据设置失效时间(固定值+一定范围的随机值)。如果不能容忍数据的不一致,必须在数据更新时,删除对应的缓存(思考:为什么不是更新缓存),但是这种情况只针对读写比非常高的情况。
缓存的常见问题优化手段
-
缓存雪崩
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。 该类问题的解决方式主要有三种: ①加锁排队。大概原理是在去数据库取数据的时候加锁排队,该方法仅仅适用于并发量不高的情况。 ②在原有失效时间基础上加一个合理的随机值(0-5分钟)。分布式场景下最常见的方式(单机也可以)。 ③给缓存加标记,在缓存失效之后更新缓存数据。
-
缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。 该类问题的主要解决方式。 ①使用布隆过滤器做过滤。该方法仅仅用于查询一个不可能存在的数据。 ②把不存在的数据也缓存起来。最佳实践:单独设置比较短的过期时间,比如说五分钟。
-
缓存预热
缓存中存放的是热点数据,热点数据又是缓存系统利用某种算法对不断访问的数据筛选淘汰出来的,在重建缓存数据的过程中,系统的性能和数据库负载都不太好,那么多好的方式就是在缓存系统启动的时候就把热点数据加载好,这个缓存预加载的手段叫做缓存预热。对于一些元数据如省市区列表,类目信息,就可以在启动的加载数据库中的全部数据。
分布式缓存架构
分布式缓存是指缓存部署在多个服务器组成的集群中,以集群方式提供缓存服务,其架构方式有两种: ①以JBosss Cache为代表的需要更新同步的分布式缓存(在所有服务器中保存相同的缓存数据)。 ②以Memcache为代表的互不通信的分布式缓存(应用程序通过一致性Hash等路由算法选择缓存服务器远程访问远程数据,可以会容易的扩容,具有良好的可伸缩性)。
异步
使用异步操作,可以大幅度改善网站的性能,使用异步的两种场景,高并发、微服务; ①高并发,在不使用消息队列的情况下,用户的请求数据直接写入数据库,在高并发的情况下会对数据库造成一定的压力,同时也使得响应延迟加剧。使用消息队列具有很好的削峰作用,在电子商务网站促销活动中,使用消息队列是常见的技术手段。 ②微服务之间调用,在微服务流行的当下,有时候我们调用其他系统的微服务接口,只是为了通知其他系统,我们不关心结果,这个时候我们可以使用单独的线程池异步调用其他系统的微服务,这样可以减少程序的响应时间。 任何可以晚点的事情都应该晚点再做。
集群
在网站高并发访问的场景洗下,使用负载均衡技术为一个应用构建一个由多台服务器组成的服务器集群,可以避免单一服务器因负载压力过大而响应缓慢。常用的负载均衡技术有以下几种: ①HTTP重定向负载均衡,不利于SEO,不推荐。 ②DNS域名解析负载均衡,许多DNS服务器还支持基于地理位置的域名解析,会将域名解析成距离用户地理最近的一个服务器地址,这样可以加快访问速度。大公司常用的手段。 ③反向代理负载均衡(应用层负载均衡),常见产品:Nginx,反向代理服务器的性能可能会成为瓶颈。 ④IP负载均衡,在内核进程完成数据分发,叫反向代理负载均衡有更好的处理性能,网卡和带宽会成为主要的瓶颈。 ⑤数据链路层负载均衡(三角传输模式),又名DR(直接路由模式),也是大型网站昌运宫的负载均衡手段,在Linux平台上最好的链路层负载均衡产品是LVS。
代码优化
网站的业务逻辑实现代码主要部署在应用服务器上,合理的优化代码也可以很好的改善网站性能。几种常用的几种代码优化方式: ①合理使用多线程,服务器的启动的线程数参考值:[任务执行时间/(任务执行时间-IO等待时间)]CPU内核数。 ②资源复用,要尽量减少那些开销很大的系统资源的创建和销毁,比如数据库连接,网络通信连接、线程、复杂对象,从编程角度,资源复用主要有两种方式,单例、对象池。 ③数据结构,前面缓存部分就已经提到了Hash表的基本原理,Hash表的读写性能在很大程度上依赖于HashCode的随机性,即HashCode越散列,Hash表的冲突就越少,目前比较好的Hash散列算法是Time33算法,算法原型为:hash(i) = hash(i-1)33+str[i]。 ④垃圾回收,比如说在JVM里,合理设置Young Generation和Old Generation的大小,尽量减少Full GC,如果设置合理的话,可以在整个运行期间做到从不进行Full GC。
存储优化
在网站应用中,海量是的数据读写对磁盘访问会造成一定的压力,虽然可以通过Cache解决一部分数据读压力,但是很多时候,磁仍然是系统最严重的瓶颈。
-
机械硬盘VS固态硬盘
这两个的区别我相信大家都知道了吧,机械硬盘是通过马达驱动磁头臂带动磁头到指定的磁盘位置访问数据,这个效率我就不用多说了吧,相反,固态硬盘的数据是存储在可以持久记忆的硅晶体上,因此可以像内存一样随机访问,而且功耗更小。
-
B+树VS. LSM树
B+树是一种专门针对磁盘存储而优化的N叉排序树,以树节点为单位存储在磁盘中,从根开始查找所需的节点编号和磁盘位置,将其加载到内存中,然后继续查找,知道找到所需数据,目前大部分关系型数据库多采用两级索引的B+树,树的层次最多为3层。
目前很多NoSQL产品采用LSM树作为主要的数据结构,LSM树可以看做是一个N阶合并树,数据的写操作都在内存中完成,并且都会创建一个新记录,这些数据在内存中仍然还是一颗排序树。在需要读的时候,总是从内存中的排序树开始搜索,如果没有找到,就从磁盘的排序树中查找。
在LSM树上进行一次数据更新不需要磁盘访问,在内存中即可完成,速度远快于B+树,当数据访问以写操作为主,而读操作则集中在最近写入的数据上时,使用LSM树可以极大程度的减少磁盘的访问次数,加快访问速度。
-
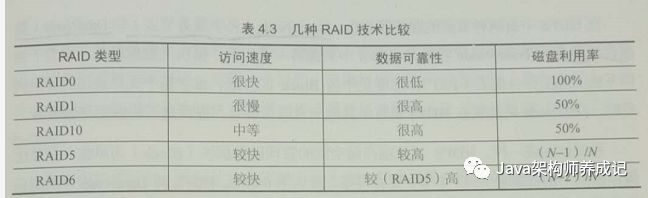
RAID VS HDFS
RAID有很多方案,这里就不细说了,关于RAID的访问速度、数据可靠性、磁盘利用率见下图:
在HDFS中,系统在整个存储集群的多台服务器上进行数据的并发读写和备份,可以看做在服务器集群规模上实现了类似RAID的功能,因此不需要磁盘RAID。

