人
已阅读
已阅读
免备案CDN加速日志全链路分析系统的实施
作者:cdnfine 来源:cdnfine 发布时间:2020-11-22
【摘要】在CDN对用户请求的内容进行加速的过程中,用户请求会经过众多环节,每个环节都会生成相应的日志。当CDN网络出现故障时,运维人员一般采用人工的方式搜索、分析用户日志,效率低下,而且分析的准确性偏低。本文设计了一套针对CDN整个链路的日志分析系统,首先在每个环节的日志里增加字段跟踪每条请求,借助Hive与ES集群,将日志长期存储并提供接口查询日志的详细内容,CDN运维人员可以检索、查看并生成故障分析报告。系统还支持人工录入故障原因,为后续的机器学习自动分析链路提供数据源。本系统已经部署在中国移动CDN平面并持续稳定运行。
【关键词】CDN;链路;日志;故障分析
1 引言
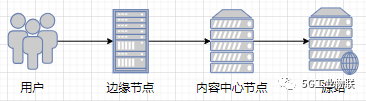
图1 CDN服务的请求链路
2 本文方案
2.1 日志收集
2.1.1 日志采集
2.1.2 日志存储
图2 本文方案的数据流向
2.2 日志检索
2.2.1 日志高级检索
2.2.2 日志溯源



图3 用户请求拓扑图
(分别对应(2)、(3)、(4)描述的场景)
2.3 故障自动分析
图4 故障分析结果
2.4 故障原因人工反馈
3 应用成效及分析
4 结论

